Provenance tracking¶
What is provenance?¶

The Arnolfini Portrait, by Jan van Eyck
The term comes originally from the art world, where it refers to the chronology of the ownership and/or location of a work of art.
Having detailed evidence of provenance can help to establish that a painting has not been altered or stolen, and is not a forgery. Wikipedia has a nice entry on the provenance of the Arnolfini Portrait by van Eyck.
The provenance (abridged) of the painting is as follows:
1434: painting dated by van Eyck; before 1516: in possession of Don Diego de Guevara, a Spanish career courtier of the Habsburgs; 1516: portrait given to Margaret of Austria, Habsburg Regent of the Netherlands; 1530: inherited by Margaret’s niece Mary of Hungary; 1558: inherited by Philip II of Spain; 1599: on display in the Alcazar Palace in Madrid; 1794: now in the Palacio Nuevo in Madrid; 1816: in London, probably plundered by a certain Colonel James Hay after the Battle of Vitoria (1813), from a coach loaded with easily portable artworks by King Joseph Bonaparte; 1841: the painting was included in a public exhibition; 1842: bought by the National Gallery, London for £600, where it remains.
More recently, the term has been applied to other fields, including archaeology, palaeontology, and science more generally, where it refers to having knowledge of all the steps involved in producing a scientific result, such as a figure, from experiment design through acquisition of raw data, and all the subsequent steps of data selection, analysis and visualization. Such information is necessary for reproduction of a given result, and can serve to establish precedence (in case of patents, Nobel prizes, etc.)
The lab notebook¶

“Lab bench” by proteinbiochemist on Flickr, CC BY-NC licence.
The traditional tool for tracking provenance information in science is the laboratory notebook.
The problem with computational science is that the number of details that must be recorded is so large that writing them down by hand is incredibly tedious and error-prone.
What should be recorded for a single run of a computational neuroscience simulation?
- the code that was run:
- the version of Matlab, Python, NEURON, NEST, etc.;
- the compilation options;
- a copy of the simulation script(s) (or the version number and repository URL, if using version control)
- copies (or URLs + version numbers) of any external modules/packages/toolboxes that are imported/included
- how it was run:
- parameters;
- input data (filename plus cryptographic identifier to be sure the data hasn’t been changed, later);
- command-line options;
- the platform on which it was run:
- operating system;
- processor architecture;
- network distribution, if using parallelization;
- output data produced (again, filename plus cryptographic identifier)
- including log files, warnings, etc.
Even if you are very conscientious, this is a lot of information to record, and when you have a deadline (for a conference, or for resubmitting an article) there will be a strong temptation to cut corners - and those are the results where it is most important to have full provenance information.
Of course, some of these data are more important than others, but the less you record, the more likely you are to have problems replicating your results later on.
The obvious solution for computation-based science is to automate the process of provenance tracking, so that it requires minimal manual input, effectively to create an automated lab notebook.
In the general case, this is not a trivial task, due to the huge diversity in scientific workflows (command-line or GUI, interactive or batch-jobs, solo or collaborative) and in computing environments (from laptops to supercomputers).
We can make a list of requirements such a system should satisfy:
- automate as much as possible, prompt the user for the rest;
- support version control, ideally by interacting with existing systems (Git, Mercurial, Subversion, Bazaar ...);
- support serial, distributed, batch simulations/analyses;
- link to, and uniquely identify, data generated by the simulation/analysis;
- support all and any (command-line driven) simulation/analysis programs;
- support both local and networked storage of simulation/analysis records.
Software tools for provenance tracking¶
A wide variety of software tools has been developed to support reproducible research and provenance tracking in computational research. Each of these tools takes, in general, one of three approaches - literate programming, workflow management systems, or environment capture.
Literate programming¶

Donald Knuth
Literate programming, introduced by Donald Knuth in the 1980s, interweaves text in a natural language, typically a description of the program logic, with source code. The file can be processed in two ways: either to produce human-readable documentation (using LateX, HTML, etc.) or to extract, possibly reorder, and then either compile or iterpret the source code.
Closely related to literate programming is the “interactive notebook” approach used by Mathematica, Sage, IPython, etc., in which the output from each snippet of source code (be it text, a figure, a table, or whatever) is included at that point in the human-readable document.
This is obviously useful for scientific provenance tracking, since the code and the results are inextricably bound together. With most systems it is also possible for the system to automatically include information about software versions, hardware configuration and input data in the final document.
The literate programming/interactive notebook approach is less likely to be appropriate in the following scenarios:
- each individual step takes hours or days to compute;
- computations must be run on parallel and/or remote, time-sharing hardware;
- code is split among many modules or packages (i.e. the front-end, “user-facing” code that is included in the final documentation is only a small fraction of the total code).
This is not to say that the literate programming approach will not prove to be a good one in these scenarios (IPython includes good support for parallelism, for example, and many tools provide support for caching of results so only the code that has changed needs to be re-run), but the current generation of tools are generally more difficult to use in these scenarios.
The following are some literate programming/interactive notebook tools that are suitable for scientific use:
- Sweave
- Sweave “is an open-source tool that allows to embed the R code for complete data analyses in LaTeX documents. The purpose is to create dynamic reports, which can be updated automatically if data or analysis change.” Sweave is specific to the R-language, and is included in every R installation.
- Emacs org mode
- Org-mode is a mode for the open-source Emacs editor which enables tranforming plain text documents into multiple output formats: HTML, PDF, LaTeX, etc. The Babel extension to org-mode enables mixing of text and code (33 programming languages supported as of version 7.7). Delescluse et al. (2011) [1] present some examples of using both org-mode and Sweave for reproducible research.
- TeXmacs
- TeXmacs is an open-source “wysiwyw (what you see is what you want) editing platform with special features for scientists”, which allows mixing text, mathematics, graphics and interactive content. TeXmacs allows embedding and executing code in many languages, including Scheme, Matlab and Python.
- IPython notebook
- IPython is an open-source environment for interactive and exploratory computing using the Python language. It has two main components: an enhanced interactive Python shell, and an architecture for interactive parallel computing. The IPython notebook provides a web-browser-based user interface that allows mixing formatted text with Python code. The Python code can be executed from the browser and the results (images, HTML, LaTeX, movies, etc.) displayed inline in the browser.
- Mathematica notebook
- Mathematica is proprietary software for symbolic and numerical mathematics, data analysis and visualization, developed by Wolfram Research. It has a notebook interface in which code and the results of executing the code are displayed together. It was part of the inspiration for the IPython notebook and the Sage mathematics system also mentioned here.
- Sage notebook
- Sage is a mathematics software system with a Python-based interface. It aims to create “a viable free open source alternative to Magma, Maple, Mathematica and Matlab.” Like IPython, Sage notebooks allow creation of interactive notebooks that mix text, code and the outputs from running code.
- Dexy
- Dexy is “a free-form literate documentation tool for writing any kind of technical document incorporating code. Dexy helps you write correct documents, and to easily maintain them over time as your code changes.” Dexy supports multiple programming and text-markup languages. Dexy is slightly different to the other tools described here in that code lives in its own files (as in a normal, non-literate-programming approach) and parts (or all) of the code can then be selectively included in the document.
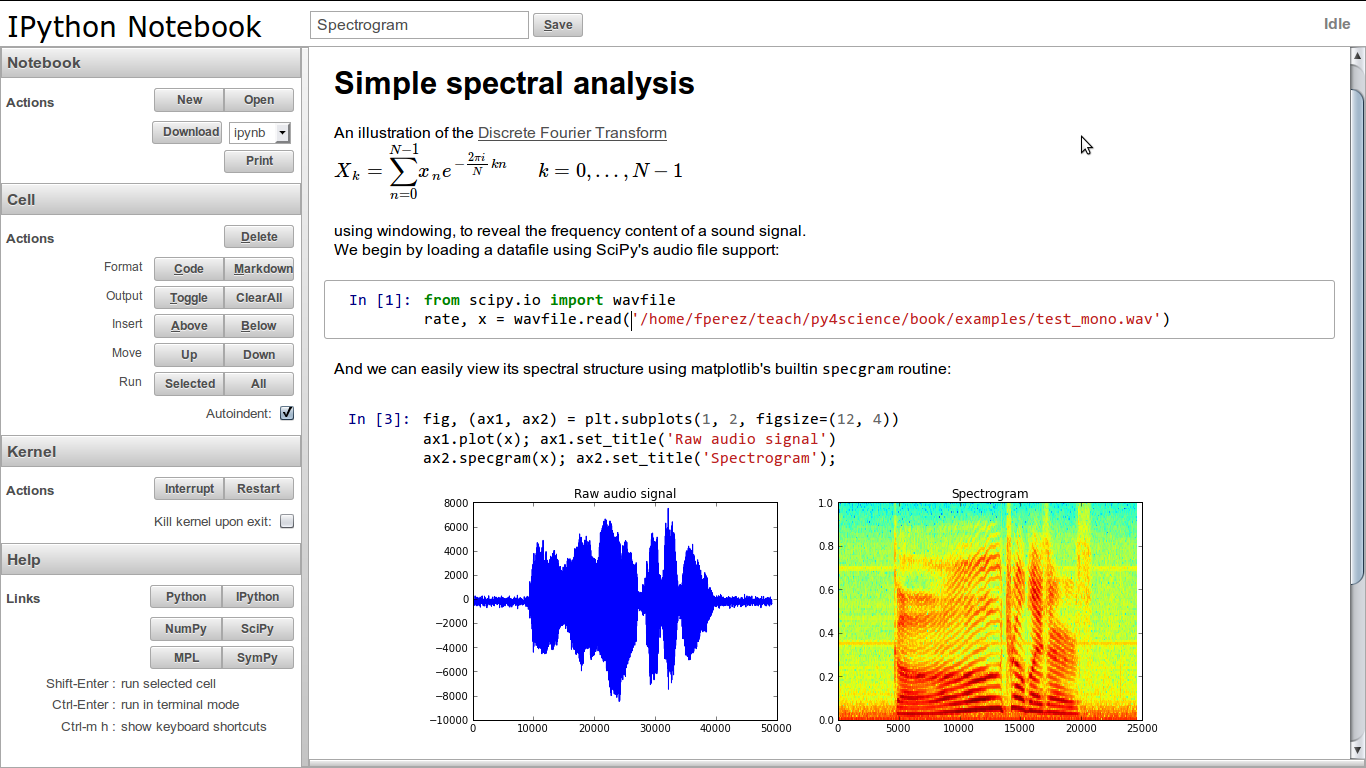
An example of using the IPython notebook
Workflow management systems¶
Where literate programming focuses on expressing computations through code, workflow management systems express computations in terms of higher-level components, each performing a small, well-defined task with well defined inputs and outputs, joined together in a pipeline.
Obviously, there is code underlying each component, but for the most part this is expected to be code written by someone else, the scientist uses the system mainly by connecting together pre-existing components, or by wrapping existing tools (command-line tools, webservices, etc.) so as to turn them into components.
Workflow management systems are popular in scientific domains where there is a certain level of standardization of data formats and analysis methods - for example in bioinformatics and any field that makes extensive use of image processing.
The advantages of workflow management systems are:
- reduces or eliminates the need for coding - pipelines can be built up using purely visual, graphical tools;
- helps with data format conversion;
- decoupling of the specification of a computation from its execution: this allows automated optimisation of pipeline execution, for example by computing different components in different environments, distributing components over multiple computing resources, caching previously-calculated results, etc.
The main disadvantage is that where there are no pre-existing components, nor easily-wrapped tools (command-line tools or webservices), for a given need, writing the code for a new component can be rather involved and require detailed knowledge of the workflow system architecture.
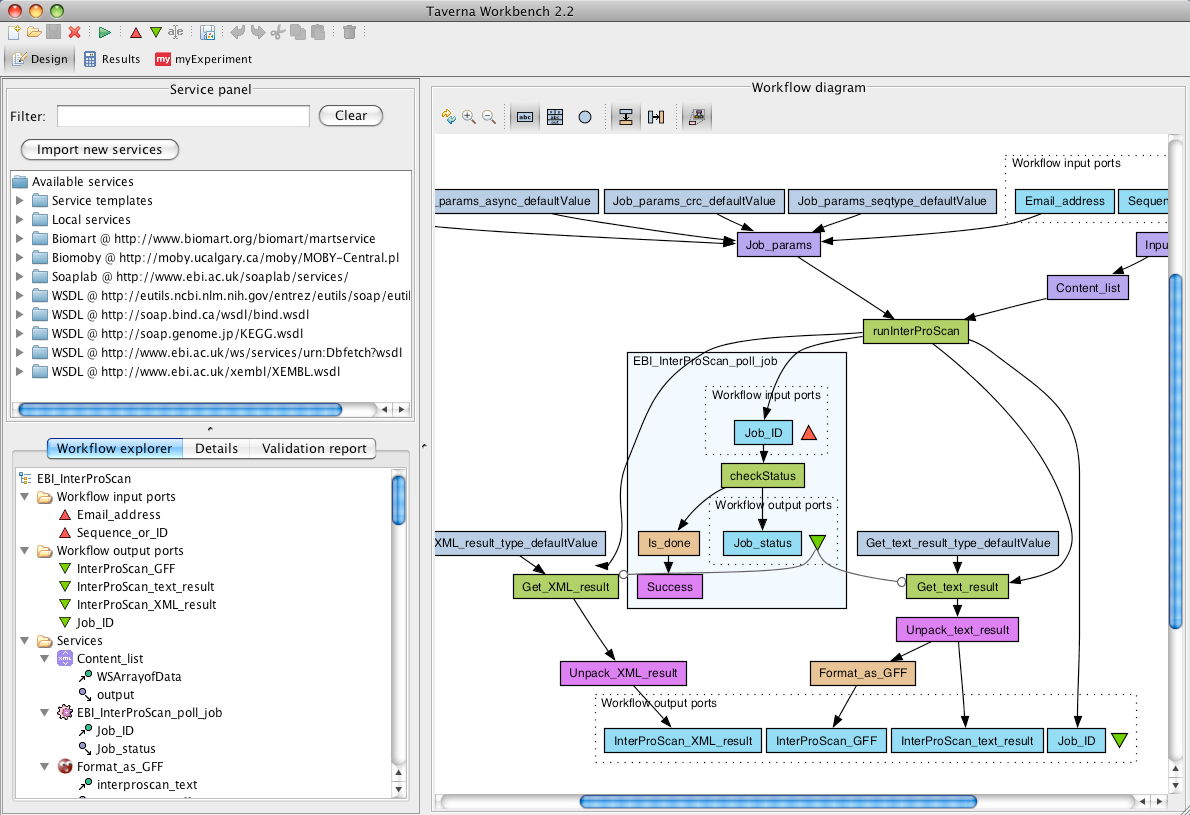
The Taverna Workbench
The following are some workflow management systems in wide use:
- Taverna
- Taverna is an open-source project mainly developed at the University of Manchester, UK, and related to the myGrid project. It is written in Java, and uses the OPM (Open Provenance Model) standard to provide provenance information: “which services were executed, when, which inputs were used and what outputs were produced.” Taverna seems to be particularly widely used in the bioinformatics, cheminformatics and astronomy communities.
- Kepler
- Kepler is an open-source project developed by a team centred on the University of California (UC Davis, UC Santa Barbara, UC San Diego). It is written in Java, and has support for components written in R and Matlab. Kepler seems to be particularly widely used in the environmental and earth sciences communities. Kepler has an optional provenance tracking module.
- Galaxy
- Galaxy “is an open, web-based platform for data intensive biomedical research”, developed mainly by groups at Penn State and Emory University. It appears to be focused specifically on bioinformatics. Galaxy seems to support provenance tracking through its “History” system.
- VisTrails
- VisTrails is an open-source project developed at the University of Utah, and written in Python. The distinctiveness of VisTrails is that it focuses on exploratory workflows: the entire history of a workflow is saved, so that it is easy to go back and forth between earlier and later versions of a workflow. Provenance information can be stored in a relational database or in XML files. VisTrails also supports a literate programming approach, providing a LaTeX package that allows links to workflows to be embedded in the document source. When the document is compiled, the workflow is executed in VisTrails and the output inserted into the document.
- LONI Pipeline
- LONI Pipeline is developed by the Laboratory of Neuro Imaging at UCLA. It is a general purpose workflow management system, but with a strong focus on neuroimaging applications. Recent versions of LONI Pipeline include a provenance manager for tracking data, workflow and execution history.
- CARMEN
- The CARMEN portal, developed by a consortium of UK universities, is a “virtual research environment to support e-Neuroscience”. It is “designed to provide services for data and processing of that data in an easy to use environment within a web browser”. Components can be written in Matlab, R, Python, Perl, Java and other languages. Provenance tracking does not appear to be automatic, but there is a system that “allows the generation of metadata from services to provide provenance information”.
Environment capture¶
The third approach to software tools for provenance tracking is in some ways the most lightweight, has the fewest restrictions on programming languages supported, and requires the least modification to computational scientists’ existing workflows.
Environment capture means capturing all the details of the scientists’ code, data and computing environment, in order to be able to reproduce a given computation at a later time.
The simplest approach is to capture the entire operating system in the form of a virtual machine (VM) image. When other scientists wish to replicate your results, you send them the VM image together with some instructions, and they can then load the image on their own computer, or run it in the cloud.
The VM image approach has the advantage of extreme simplicity, both in capturing the environment (all virtual machine software has a “snapshot” function which captures the system state exactly at one point in time) and in replaying the computation later.
The main disadvantages are:
- VM images are often very large files, of several GB in size;
- there is a risk that the results will be highly sensitive to the particular configuration of the VM, and will not be easily reproducible on different hardware or with different versions of libraries, i.e. the results may be highly replicable but not reproducible;
- it is not possible to index, search or analyse the provenance information;
- it requires the original computations to use virtualisation technologies, which inevitable have a performance penalty, even if small;
- the approach is challenging in a context of distributed computations spread over multiple machines.
An interesting tool which supports a more lightweight approach (in terms of filesize) than capturing an entire VM image, and which furthermore does not require use of virtualization technology, is CDE. CDE stands for “Code, Data, Environment” and is developed by Philip Guo. CDE works only on Linux, but will work with any command-line launched programme. After installing CDE, prepend your usual command-line invocation with the cde command, e.g.:
$ cde nrngui init.hoc
CDE will run the programs as usual, but will also automatically detect all files (executables, libraries, data files, etc.) accessed during program execution and package them up in a compressed directory. This package can then be unpacked on any modern x86 Linux machine and the same commands run, using the versions of libraries and other files contained in the package, not those on the new system.
The advantages of using CDE are:
- more lightweight than the full VM approach, generates much smaller files
- doesn’t have performance penalty of using VM
- minimal changes to existing workflow (use on your current computers)
The disadvantages are in general shared with the VM approach:
- the risk of results being highly sensitive to the particular configuration of your computer
- the difficulty in indexing, searching or analyzing the provenance information
In addition, CDE works only on modern versions of Linux.
An alternative to capturing the entire experiment context (code, data, environment) as a binary snapshot is to capture all the information needed to recreate the context. This approach is taken by Sumatra.
Note
Sumatra is developed by the author of this tutorial. I aim to be objective, but cannot guarantee this!
The advantages of this approach are:
- it is possible to index, search, analyse the provenance information;
- it allows testing whether changing the hardware/software configuration affects the results;
- it works fine for distributed, parallel computations;
- it requires minimal changes to existing workflows.
The main disadvantages, compared to the VM approach, are:
- a risk of not capturing all the context;
- doesn’t offer “plug-and-play” replicability like VMs, CDE - the context must be reconstructed based on the captured metadata if you want to replicate the computation on another computer.
An interesting approach would be to combine Sumatra and CDE, so as to have both information about the code, data, libraries, etc. and copies of all the libraries in binary format.
An introduction to Sumatra¶
I will now give a more in-depth introduction to Sumatra. Sumatra is a Python package to enable systematic capture of the context of numerical simulations/analyses. It can be used directly in your own Python code or as the basis for interfaces that work with non-Python code.
Currently there is a command line interface smt, which is mainly for configuring your project and launching computations, and a web interface which is mainly for browsing and inspecting both the experiment outputs and the captured provenance information.
The intention is that in the future Sumatra could be integrated into existing GUI-based tools or new desktop/web-based GUIs written from scratch.
Installation¶
Installing Sumatra is easy if you already have Python and its associated tools:
Setting-up project tracking¶
Suppose you already have a simulation project, and are using Mercurial for version control. In your working directory (which contains your Mercurial working copy), use the smt init command to start tracking your project with Sumatra.
$ cd myproject
$ smt init MyProject
This creates a sub-directory, .smt which contains configuration information for Sumatra and a database which will contain simulation records (it is possible to specify a different location for the database, or to use an already existing one, but this is the default).
Capturing experimental context¶
Suppose that you usually run your simulation as follows:
$ python main.py default.param
To run it with automatic capture of the experiment context (code, data, environment):
$ smt run --executable=python --main=main.py default.param
or, you can set defaults:
$ smt configure --executable=python --main=main.py
and then run simply:
$ smt run default.param
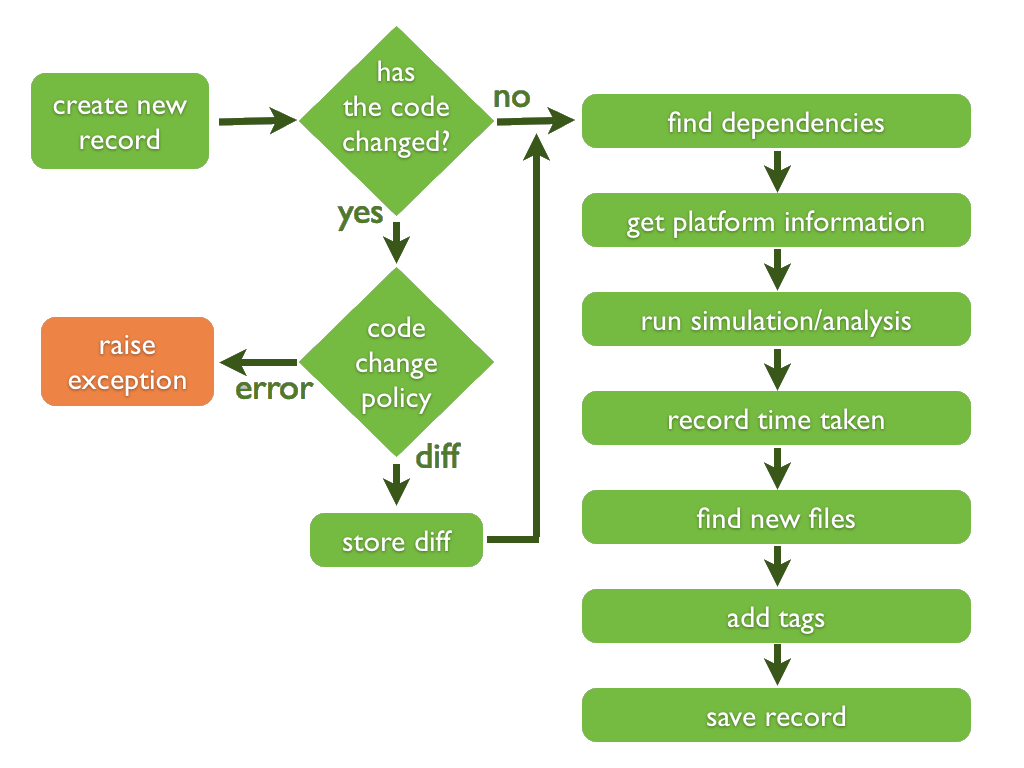
What happens when you do this is illustrated in the following figure:
Browsing the list of simulations¶
To see a list of simulations you have run, use the smt list command:
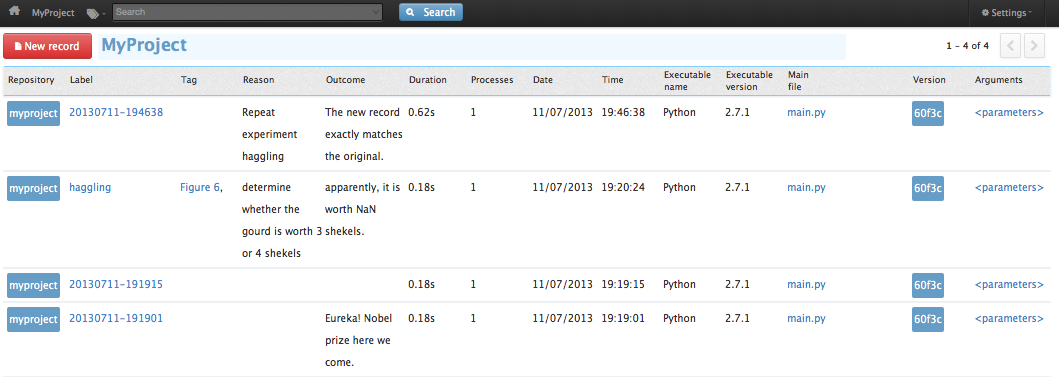
$ smt list
20130711-191915
20130711-191901
Each line of output is the label of a simulation record. Labels should be unique within a project. By default, Sumatra generates a label for you based on the timestamp, but it is also possible to specify your own label, as well as to add other information that might be useful later, such as the reason for performing this particular simulation:
$ smt run --label=haggling --reason="determine whether the gourd is worth 3 or 4 shekels" romans.param
(see Monty Python’s Life of Brian to understand the gourd reference).
After the simulation has finished, you can add further information, such as a qualitative assessment of the outcome, or a tag for later searching:
$ smt comment "apparently, it is worth NaN shekels."
$ smt tag "Figure 6"
This adds the comment and tag to the most recent simulation record. If you wish to annotate an older record, specify its label (this is why labels should be unique):
$ smt comment 20130711-191901 "Eureka! Nobel prize here we come."
To get more information about your simulations, the smt list command takes various options:
$ smt list -l
--------------------------------------------------------------------------------
Label : 20130711-191901
Timestamp : 2013-07-11 19:19:01.678901
Reason :
Outcome : Eureka! Nobel prize here we come.
Duration : 0.183968782425
Repository : MercurialRepository at /path/to/myproject
Main_File : main.py
Version : 60f3cdd50431
Script_Arguments : <parameters>
Executable : Python (version: 2.7.1) at /usr/bin/python
Parameters : n = 100 # number of values to draw
: seed = 65785 # seed for random number generator
: distr = "uniform" # statistical distribution to draw values from
Input_Data : []
Launch_Mode : serial
Output_Data : [example2.dat(43a47cb379df2a7008fdeb38c6172278d000fdc4)]
User : Andrew Davison <andrew.davison@unic.cnrs-gif.fr>
Tags :
.
.
.
But in general, it is better to use the web interface to inspect this information. The web interface is launched with:
$ smtweb
This will run a small, local webserver on your machine and open a new browser tab letting you see the records in the Sumatra database:

Replicating previous simulations¶
To re-run a previous simulation, use the smt repeat command:
$ smt repeat haggling
The new record exactly matches the original.
This command will use the version control system to checkout the version of the code that was used for the original simulation, run the simulation, and then compare the simulation outputs to the outputs from the original.
It does not attempt to match the rest of the environment (versions of libraries, processor architecture, etc.) and so this is a useful tool for checking the robustness of your results: if you have upgraded some library, do you still get the same results?
If the output data do not match, Sumatra will provide a detailed report of what is different between the two simulation runs.
Getting help¶
Sumatra has full documentation at http://packages.python.org/Sumatra/. The smt command also has its own built-in documentation. With no arguments it produces a list of available subcommands, while the smt help command can be used to get detailed help on each of the subcommands.
$ smt
Usage: smt <subcommand> [options] [args]
Simulation/analysis management tool version 0.6.0
Available subcommands:
init
configure
info
run
list
delete
comment
tag
repeat
diff
help
export
upgrade
sync
migrate
Finding dependencies¶
Most of the metadata captured by smt is independent of the programming language used. Capturing the code dependencies (versions of software libaries, etc.) does however requires a per-language implementation.
Sumatra currently supports: Python, Matlab, Hoc (the language for the NEURON simulator) and the script language for the GENESIS 2 simulator. Support for Octave, R, C and C++ is planned.
Version finding is based on various heuristics:
- some language specific (e.g. in Python check for a variable called __version__ or a function called get_version(), etc.)
- some generic (e.g. where dependency code is under version control or managed by a package manager)
Linking to input and output data¶
Part of the information Sumatra stores is the paths to input and output data. Currently, only data on the local filesystem is supported. In future, we plan to support data from relational databases, web-based databases, etc.) Sumatra stores the cryptographic signature of each data file to ensure file contents at a later date are the same as immediately after the simulation (this will catch overwriting of the file, etc.).
Record stores¶
Sumatra has multiple ways to store experiment records, to support both solo/local and collaborative/distributed projects:
- for local or network filesystems, there is a record store based on SQLite or PostgreSQL
- for collaboration over the internet, there is a server application providing a remote recordstore communicating over HTTP
Version control support¶
Sumatra requires your code to be under version control. Currently supported systems are Subversion, Git, Mercurial and Bazaar.
Summary¶
In summary, Sumatra is a toolbox for automated context capture for computational experiments. Basic metadata is captured for any language, logging dependencies requires a language-specific plugin.
Using the smt command:
- requires no changes to existing code
- requires minimal changes to your existing workflow
thus, we hope, meeting our original criterion of:
“Be very easy to use, or only the very conscientious will use it”